
浏览器缓存理论
缓存可以说是性能优化中简单高效的一种优化方式,可以缩短网页请求资源的距离,减少延迟,并且由于缓存文件可以重复利用,还可以减少带宽,降低网络负荷。
缓存位置
Service Worker
Service Worker 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能,必须基于HTTPS协议。Service Worker 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。
Service Worker 实现缓存功能一般分为三个步骤:
- 注册service Worker
- 监听install时间
- 缓存需要的文件
缓存之后,Service Worker 可以拦截下次的请求来查询是否存在缓存。如果没有命中缓存,需要使用fetch函数去请求数据(根据缓存优先级来获取数据;但是还是现实在Service Worker中获取的内容)。
Memory Cache
Memory Cache 是内存中的缓存,主要包括当前页面中已经抓取的资源(已经下载的样式、脚本、图片等)。在内存中读取缓存速度快,读取高效,但是持续性很短,会跟随进程的释放而释放。
以下几种情况下资源会被缓存在Memory Cache中:
- 被预加载器(Preloader)获取的。
- 预加载指令()
- 之前的DOM阶段或者CSS规则引起的请求。
但是Memory Cache不会轻易的命中一个请求,除了要有匹配的URL,还要有相同的资源类型、CORS模式以及一些其他特性。
Memory Cache匹配规则在标准中没有详尽的描述,所以不同的浏览器内核在实现上会有所不同。
Memory Cache是不关心HTTP语义的,比如Cache-Control: max-age=0的资源,仍然可以在同一个导航中被重用。但是在特定的情况下,Memory Cache会遵守Cache-Control: no-store指令,不缓存相应的资源。
Disk Cache
Disk Cache 也就是我们经常说的HTTP Cache,顾名思义,它是存储在硬盘中的缓存,具有较强的时效性和大的容量性。
浏览器会把哪些文件丢进内存中?哪些丢进硬盘中?关于这点,网上说法不一,不过以下观点比较靠得住:
- 对于大文件来说,大概率是不存储在内存中的,反之优先
- 当前系统内存使用率高的话,文件优先存储进硬盘
Push Cache
Push Cache(推送缓存)是 HTTP/2 中的内容,当以上三种缓存都没有命中时,它才会被使用。它只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在Chrome浏览器中只有5分钟左右,同时它也并非严格执行HTTP头中的缓存指令。
- 所有的资源都能被推送,并且能够被缓存,但是 Edge 和 Safari 浏览器支持相对比较差
- 可以推送 no-cache 和 no-store 的资源
- 一旦连接被关闭,Push Cache 就被释放
- 多个页面可以使用同一个HTTP/2的连接,也就可以使用同一个Push Cache。这主要还是依赖浏览器的实现而定,出于对性能的考虑,有的浏览器会对相同域名但不同的tab标签使用同一个HTTP连接。
- Push Cache 中的缓存只能被使用一次
- 浏览器可以拒绝接受已经存在的资源推送
- 你可以给其他域名推送资源
如果以上四种缓存都没有命中的话,那么只能发起请求来获取资源了。
缓存过程分析
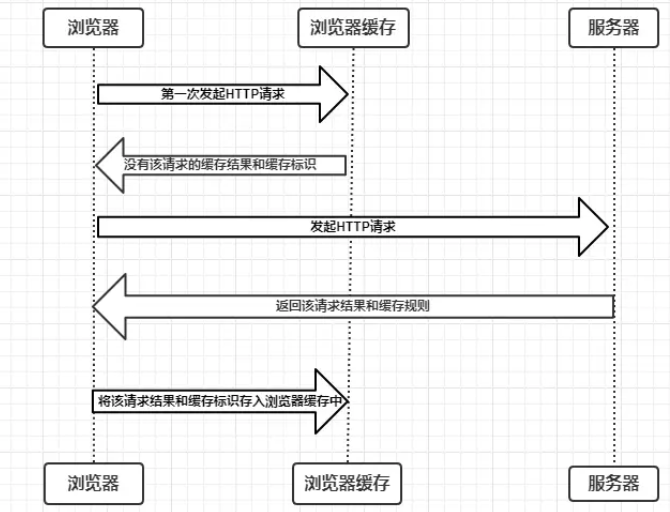
由上图可知:
- 浏览器每次发起请求,都会先在浏览器缓存中查找该请求的结果以及缓存标识
- 浏览器每次拿到返回的请求结果都会将该结果和缓存标识存入浏览器缓存中
以上两点结论就是浏览器缓存机制的关键,它确保了每个请求的缓存存入与读取